2025 国际工程智能大会奉献了 6 场代表着工程智能领域前沿水准的主旨报告,6 位顶级专家学者对工程智能关键领域的创新探索与深度思考,给现场嘉宾和观众带来了深刻的启迪。这 6 场主旨报告是 2025 国际工程智能大会重要的思想沉淀,将陆续与全球工程智能领域的同道分享。
名家讲坛第四期重磅上线!下文为报告精华整理,关注“同济大学工程智能研究院”微信公众号获取完整演讲视频。
大语言模型可靠智能体研究
俞凯
上海交通大学计算机学院特聘教授
机器智能研究所所长

非常高兴今天有机会与大家分享我们在大语言模型可靠智能体方面的一些研究,探讨一个新的完全不一样的研究范式。田老师之前的报告已经指出,交互环境在未来大语言模型的应用中至关重要,这也引出了我今天报告的核心。
首先,我们探讨大语言模型在智能体时代所面临的“幻觉”问题有何不同。从大语言模型到智能体时代,这个过程有一个范式性的变革。大语言模型以语言生成为主,主要是“模型生成,人类校准”的模式。而进入智能体时代,转变为“模型生成,模型校准”,然后通过多轮与环境交互,最终向人交付结果。这意味着模型从“生成智能”转向“执行智能”。

因为校准主体变为模型自身,可能产生的错误也千差万别。在大语言模型时代,我们讲的幻觉多指事实性和知识性的幻觉,而在智能体时代,由于涉及与物理环境的交互,它产生的幻觉可能要远大于此,因为它有可能对物理环境产生伤害,并且错误会在交互过程中被放大在在这个过程中,我们也难以定义一个“正确答案”。
原先我们讲的幻觉,是有文本参考答案作为标准去对比来得到所谓的事实错误,而真正到了智能体时代,我们只能讲什么东西是合理的。例如,当用户要求设置一个9点响的闹钟,如果系统因无相应APP而回复“无法设置”,这也是一种合理回应。此时,“非预期行为”成为定义幻觉的本身。而所有的幻觉基本上都来源于我们这一套技术框架会产生不确定性,这是大部分人的观点。
绝大部分主流观点认为,不确定性的来源主要有两方面:一是内在原因,模型本身作为概率生成模型的输出具有不确定性;二是外在原因,训练数据的不准确性及不充分性。我们常说解决幻觉的办法就是把数据搞准,或者我们通过加上一些工具,这样两个归因构成了到现在为止绝大多数解决幻觉问题的技术方案。所以我们就看到了两个范式——其实是三个,还有直接加领域内数据,这不算是一种科学的范式,除此之外我们有两个范式:第一种是通过工具去增强,大语言模型内部知识不准,通过外部调用工具扩展它的知识边界;第二种是估计模型输出的置信度,高置信度时继续输出,低时停止输出,对我们的概率的质量去进行估计。
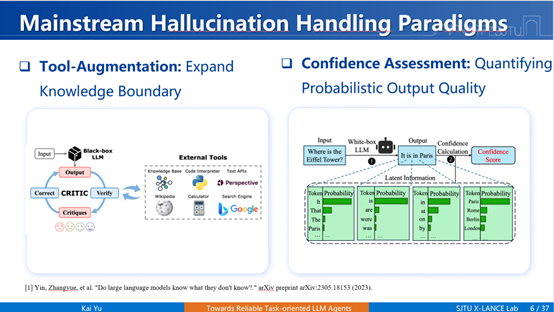
这两种方法是否真的解决了幻觉问题呢?
第一种方法是“工具增强”,我们希望通过外部工具来弥补模型知识的不足。然而,引入工具也带来了新的问题——“工具幻觉”,具体表现为两种:第一种是冗余调用,不需要调用却非要调用它,带来了更高的成本消耗;第二种是错误调用,工具调用错了或者参数调用错了等等。由于工具幻觉导致最后任务不能完成,我们叫它“任务幻觉”。数据显示,即使模型规模扩大,工具幻觉的比例仍高达40%左右,增加数据量甚至可能加剧这一问题。这说明,该方法只是将幻觉从模型内部引到了工具调用上,不能真正意义的去解决问题,虽然它有所帮助,但只能一定程度上去缓解。
第二种方法是“置信度估计”,我们假设低置信度代表模型的低可靠性。但我们研究发现,大模型存在类似人类精神领域的“妄想”现象,即对错误答案表现出高置信度,我们发现无论如何扩展模型或数据,妄想率始终存在并且维持至少20%–30%之间。
由此可见,两种主流范式均未能根本解决幻觉问题,它们有一些共同点:第一,它们都认为幻觉是有害的,应该消除;第二,我应该追求一种完全消除幻觉的办法。但真的是这样吗?有没有可能不确定性本身它就根本不能够被消除掉呢?

不管是人类通讯系统还是工业通讯系统,不确定性是一种本质属性,无法也不应被完全消除。语言歧义、手势模糊、环境噪音等都带来不确定性,然而正是这些不确定性,在很多时候提高了沟通效率。语言学研究表明,在沟通时,说话者倾向于表达简洁,听话者偏好表达明确,最后就导致了一个结果,就是词的频度和词的多义性相乘是一个常数。所以我们就会发现,不确定性不仅是不可消除的,而且还是不可或缺的。
那么人类是怎么解决这件事的呢?有一个著名的例子是“9.9与9.11哪个大”,我们实事求是的做了一个实验,如果你明确的问模型哪一个数字大,模型会回答9.9大,但如果你问哪一个版本大,模型会告诉你9.11大。若模型基于其训练数据(如大量代码版本比较)理解为版本号比较,并回答9.11更大,这并非错误,而是它能够真正意义给了一个先验知识,只是它的“世界模型”与人类没有对齐。问题可能不在于模型幻觉,而在于人类提供的上下文信息不足。
人类在面对不确定性时,并不是两阶段的“生成–校准”机制,而是将“知道感”与回复在同一动作空间中一体化完成。受此启发,我们提出一种“认知型用户界面”方法,其核心是在强化学习框架中引入“不行动(do nothing)”选项。这并非简单工程技巧,而是对人类元认知机制的模仿。“do nothing”在大语言模型中具有核心地位,它是一种平衡效用,即性价比效用的平衡值。大语言模型的所有训练,本质上都可视为在优化其有用性的同时,降低其交互成本。
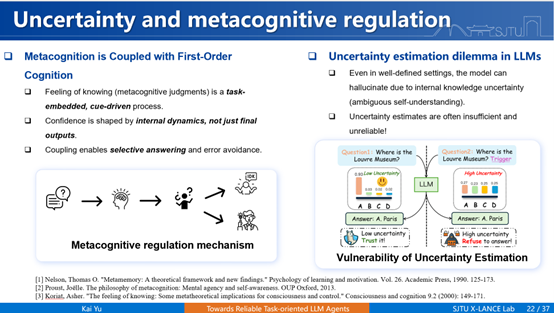
早先没有智能体时,错误是最大的交互成本。有了智能体后,错误不一定是最大交互成本,最终的错误加上效率共同构成交互成本。可靠性并非一定要避免所有错误,就像歧义问题不一定需要完全避免,可靠性的真正来源是在行动上优化性价比。
据此,我们提出了一个叫做“可靠性对齐”的框架。该框架同以前追求更高正确率的做法不同,而是将“拒绝回答”“调用工具”等负责任的回应也视为合理行为。例如,100个问题中回答对70个,正确率70%;若其余30个问题均以负责任方式回应(如告知“不会”),则负责任度为100%。系统的有效可靠性由“有用性”和“负责任度”共同决定。基于此,我们得到了一个新的优化框架。它的做法是:第一,引入“拒绝”的动作;第二,在强化学习框架下,将其与回答动作置于同等地位进行统一优化。我们称之为RLKF。
优化结果是:在知识和工具调用层面的幻觉率大幅降低。在数值推理任务上,一个Llama-7B参数模型比GPT-4o的幻觉度小很多。在更接近现实的工具调用任务中,通过可靠性对齐,8B模型的幻觉度也由以前的61.5%下降至15.6%,远好于ChatGPT的水平。类似地,我们将其应用于多轮交互中,我们知道长链路交互会放大错误。
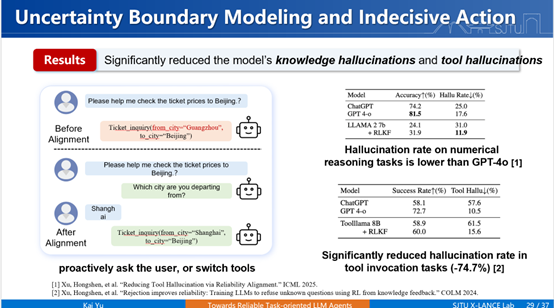
我们在多轮交互中不仅引入拒绝,还设法定义不确定性区间进行优化。它的优化方式和刚才是类似的,基本在强化学习框架下引入技巧。最终结果体现在多轮任务(如查询天气、餐馆)中,目标准确率(所有意图串联全部正确)从原来的18%提升至50%以上。这也几乎超过了我们在一个简单任务上大模型的可靠度。可靠度很重要:即使平均正确度达90%,但若10%是胡乱回答,会被认为不靠谱;另一个正确度80%,但剩下20%不乱说,则被视为靠谱。我们的目标就是实现靠谱的智能体。
总结一下:幻觉本身源于不确定性,而不确定性本质是不可避免和不可或缺的,因为它是通讯的本质。我们希望提升一种新型架构,在智能体框架下能够知道不确定性并有效建模,最终实现可靠的用户交互。
这就是报告的全部内容。谢谢大家。
本主旨演讲内容仅限学术交流之用,不得随意转载、编辑。

 English
English





