2025 国际工程智能大会奉献了 6 场代表着工程智能领域前沿水准的主旨报告,6 位顶级专家学者对工程智能关键领域的创新探索与深度思考,给现场嘉宾和观众带来了深刻的启迪。这 6 场主旨报告是 2025 国际工程智能大会重要的思想沉淀,将陆续与全球工程智能领域的同道分享。
名家讲坛第二期重磅上线!下文为报告精华整理,关注“同济大学工程智能研究院”微信公众号获取完整演讲视频。
世界模型:初步的探索与思考
田奇
华为终端BG首席科学家
光明实验室主任
国际欧亚科学院院士

大模型的发展如火如荼,一日千里。身为行业内的从业者,我也时刻感受到这种竞争的激烈与紧迫。我们团队自2020年在公司立项启动“盘古大模型”以来,投入了大量时间进行探索。时至今日,AI大模型已成为深入千行百业、重塑千行百业的关键力量,国内外也不断涌现出各类大模型与智能体(Agent)。
在这样的背景下,我们主要围绕两个问题展开思考:第一,做什么?即:大模型是否是AI的终极形态?如果不是,它的未来的形态应该是什么?第二,怎么做?怎么推动大模型走向未来的形态?当前最重要、最困难的问题是什么?
从长期来看,我们认为人工智能的发展目标是通用人工智能(AGI)。与概念性的定义不同,我们更倾向于采用形式化定义:即在给定状态、动作、转移函数和奖励函数的前提下,智能系统的目标是学习并执行最优策略,以实现长期回报最大化。
过去十余年的实践表明,这种形式化定义的做法已经在多个关键系统中得到验证。从AlphaGo、AlphaStar到以ChatGPT为代表的大模型系统都采用了相似的形式化定义,其共性在于:一是一个好的交互环境,二是具备足够能力的基础模型,二者共同构成了实现AGI的基石。
在终端领域,按照这种形式化的定义分解,我们围绕“小艺超级智能体”持续推进相关探索。但客观来看,距离真正意义上的通用智能仍存在明显差距,主要体现在两个方面。
第一,在模型层面,推理能力还比较有限,且针对天然多模态的终端场景,多模态模型的理解与生成范式未统一。第二,在交互环境层面,真实性与交互性无法兼顾。

我们注意到,终端产业与人工智能结合,孵化了一批具备“实时在线”特性的设备形态,例如AI眼镜、可穿戴设备等。这类设备能够理解周边的物理世界,这与当前的AI大模型能力是匹配的。在未来,终端产业会走向具身智能,具身智能属于高门槛、大空间、长周期的产业,需要结合AI大模型来打造爆款商业应用。
华为比较适合做这方面,我们发布了AI智能体白皮书,按用户体验进行了智能分级,核心是AI服务于人、与人协作,关键还是让人来做决定。当前业界对具身智能持有不同观点,这也是我们探索世界模型的原因。同时目前关于世界模型的具体定义学界也尚未完全统一。

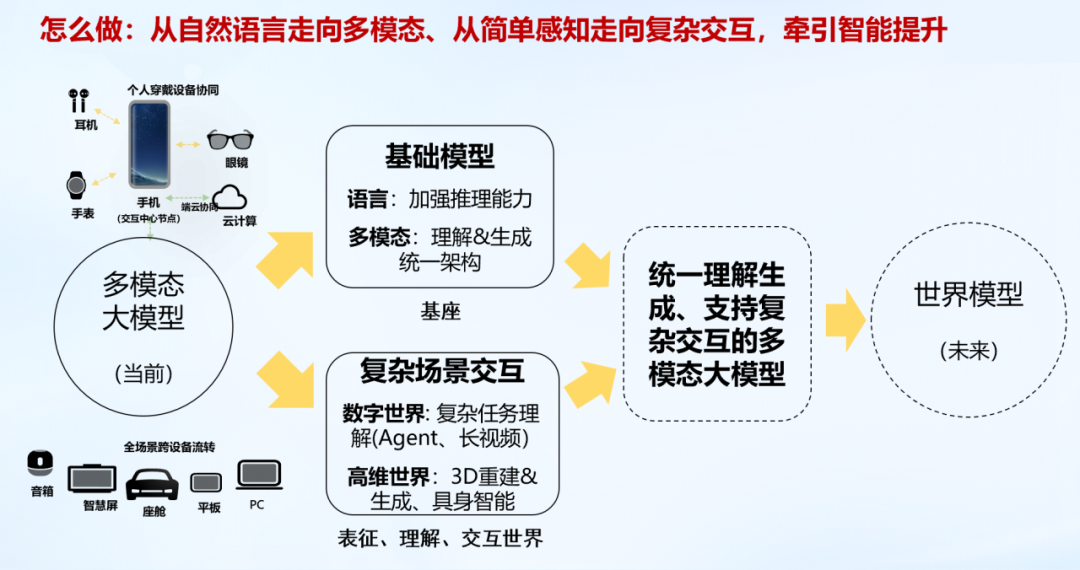
接下来探讨“怎么做”的问题。在终端行业,我们围绕手机、手表、眼镜等设备,它们天然是是多模态感知的,因此我们需从单纯的自然语言走向多模态,并从过去的简单感知、简单分类走向复杂场景交互。
因此我们的工作可以具体分为两方面:
第一,在基础模型层面,我们主要关注语言模型在端侧的应用,要加强其推理能力。在多模态方面,希望它的理解和生成能从过去分离的架构能够走向统一。
第二,在复杂场景交互层面,也是分为两条线走:一条是复杂任务的理解,主要是长视频理解;另外一条是从二维走向高维,聚焦在三维重建与生成和具身智能方面。
基础模型与复杂场景的交互构成AGI的两大基石。在这两个方面取得突破后,我们希望构建统一理解与生成、支持复杂交互的多模态大模型。
我们聚焦在做的事情,是把前沿研究和业务的落地相结合起来。
在基础模型方面,我们比较关注端侧模型在终端场景的低时延、高可靠需求,以及端侧模型对自我能力边界的认知和如何做好端云协同;在多模态大模型方面,我们关注在降低部署成本和训练成本的情况下,需要统一哪些任务。
在复杂场景交互方面,我们主要做长视频理解,我认为这是未来或者现在对多模态这个领域的新的挑战,同时三维重建与生成方面也在推进中。
接下来,给大家快速汇报一下我们在基础模型和复杂场景交互这两个方向的一些想法和进展。
在语言模型方面,我们持续优化端侧模型,我们选择 Transformer 架构,通过超8万亿Token的筛选后高质量训练数据进行训练,已在0.56B参数规模上实现显著提升。
在多模态模型方面,我们希望把理解和生成进一步的统一,这面临模型架构、规模与目标不一致的挑战,我们正从统一多模态Tokenizer、统一架构与端侧设备与物理世界交互等方进行尝试。
在长视频理解上,我们已实现对大模型对《唐山大地震》这类长视频的深度理解,并生成以主角方登为第一人称进行剧情描述的短视频,精准还原了人物关系与核心情节。
最后,在3D生成方面,我们实现了单图输入、秒级生成高质量3D模型,并支持场景无限扩展,在渲染速度与交互仿真方面取得行业领先成果。
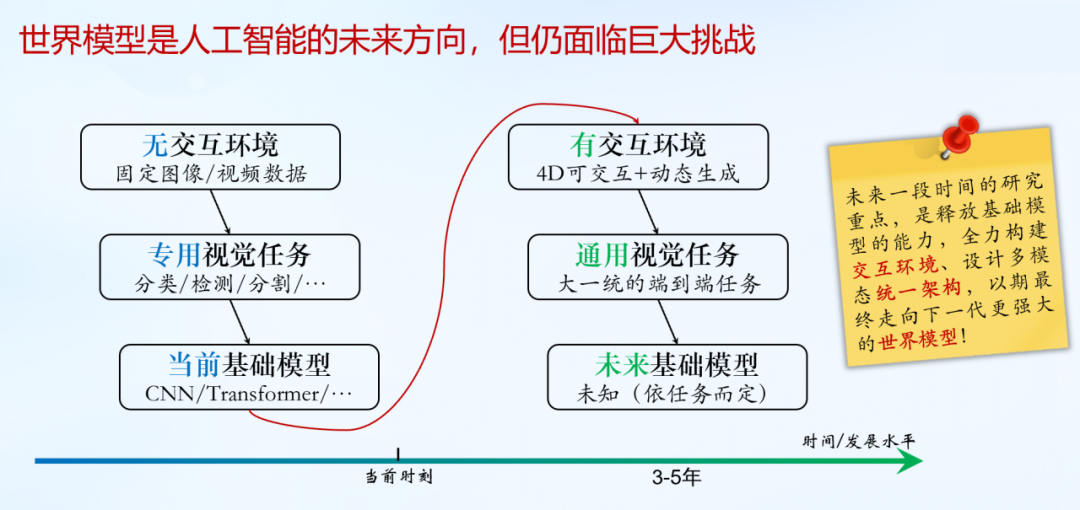
总结而言,我们认为AI大模型的下一步是世界模型,但面临诸多挑战。我们希望从过去没有交互的环境走向更好的交互环境,同时从专用的视觉任务走向大一统的端到端任务,希望全力构建并释放基础模型的能力,全力打造交互环境,设计多模态的统一架构,走向下一代更强大的视觉模型。
本主旨演讲内容仅限学术交流之用,不得随意转载、编辑。

 English
English





